Tablespaces is a simple, useful and arguably under-appreciated feature of PostgreSQL. They allow DBAs to accomodate growing databases, tables with data different from others, indexes that need to be super fast and so on. Read on to learn more about how to you can use tablespaces in Postgres.
What is a Tablespace?
Let’s start by initialising a PostgreSQL data directory. Here’s how to do that:
/tmp$ pg_ctl -D data initdbThis creates a directory, named “data”, that contains everything needed to start a PostgreSQL server. The contents of this directory look like this:
/tmp$ ls -lF data
total 112
drwx------ 5 alice alice 4096 May 8 10:53 base/
drwx------ 2 alice alice 4096 May 8 10:53 global/
drwx------ 2 alice alice 4096 May 8 10:53 pg_commit_ts/
drwx------ 2 alice alice 4096 May 8 10:53 pg_dynshmem/
-rw------- 1 alice alice 4513 May 8 10:53 pg_hba.conf
-rw------- 1 alice alice 1636 May 8 10:53 pg_ident.conf
drwx------ 4 alice alice 4096 May 8 10:53 pg_logical/
drwx------ 4 alice alice 4096 May 8 10:53 pg_multixact/
drwx------ 2 alice alice 4096 May 8 10:53 pg_notify/
drwx------ 2 alice alice 4096 May 8 10:53 pg_replslot/
drwx------ 2 alice alice 4096 May 8 10:53 pg_serial/
drwx------ 2 alice alice 4096 May 8 10:53 pg_snapshots/
drwx------ 2 alice alice 4096 May 8 10:53 pg_stat/
drwx------ 2 alice alice 4096 May 8 10:53 pg_stat_tmp/
drwx------ 2 alice alice 4096 May 8 10:53 pg_subtrans/
drwx------ 2 alice alice 4096 May 8 10:53 pg_tblspc/
drwx------ 2 alice alice 4096 May 8 10:53 pg_twophase/
-rw------- 1 alice alice 3 May 8 10:53 PG_VERSION
drwx------ 3 alice alice 4096 May 8 10:53 pg_wal/
drwx------ 2 alice alice 4096 May 8 10:53 pg_xact/
-rw------- 1 alice alice 88 May 8 10:53 postgresql.auto.conf
-rw------- 1 alice alice 22767 May 8 10:53 postgresql.confThis is self-contained, including the configuration files. All the data for all the databases, as well as items like WAL files, notification queues and so on live in this directory. Needless to say, these files must be managed only via the PostgreSQL server. This directory is, or rather can be used as, the famous $PGDATA.
To bring up a server to serve off this directory, you can:
/tmp$ pg_ctl -D data start
waiting for server to start....2018-05-08 11:00:56.338 IST [1816] LOG: listening on IPv6 address "::1", port 5500
2018-05-08 11:00:56.338 IST [1816] LOG: listening on IPv4 address "127.0.0.1", port 5500
2018-05-08 11:00:56.341 IST [1816] LOG: listening on Unix socket "/tmp/.s.PGSQL.5500"
2018-05-08 11:00:56.353 IST [1817] LOG: database system was shut down at 2018-05-08 10:53:50 IST
2018-05-08 11:00:56.362 IST [1816] LOG: database system is ready to accept connections
done
server startedBy default, when you create objects (like tables, indexes) which need on-disk storage, the Postgres server creates the required files somewhere inside $PGDATA. Turns out, this is actually a two step process, and actually goes like this: By default the Postgres server creates the required files in the default tablespace called pg_default, the location of which is the data directory $PGDATA.
Tablespaces are, in short, the way to tell the Postgres server where to place the physical files for SQL objects.
Tablespaces do not affect the logical SQL namespaces that the objects live in (like databases, schema, table, index) that the application developer sees. You cannot, for example, have 2 tables with the same name in the same schema just because they are in different tablespaces.
The Default Tablespaces
psql has a “\db+” command which lists tablespace in detail. Let’s have a look:
/tmp$ psql -h /tmp -p 5500 postgres
psql (10.3 (Debian 10.3-1.pgdg90+1))
Type "help" for help.
postgres=# \db+
List of tablespaces
Name | Owner | Location | Access privileges | Options | Size | Description
------------+-------+----------+-------------------+---------+--------+-------------
pg_default | alice | | | | 22 MB |
pg_global | alice | | | | 573 kB |
(2 rows)
postgres=#This says there are two tablespaces, owned by the user who did the initdb. But why two? Let’s refer to the fine manual:
Two tablespaces are automatically created when the database cluster is initialized. The pg_global tablespace is used for shared system catalogs. The pg_default tablespace is the default tablespace of the template1 and template0 databases (and, therefore, will be the default tablespace for other databases as well, unless overridden by a TABLESPACE clause in CREATE DATABASE).
The location of the default tablespaces is the same as the data directory, or $PGDATA.
Basically then, by default the server is going to place objects into the pg_default tablespace, which maps to the data directory itself.
Creating Tablespaces
Let’s try creating a new tablespace and see what happens – but first, we need to create a directory somewhere in the filesystem:
/tmp$ mkdir /tmp/space2And then do:
postgres=# create tablespace space2 location '/tmp/space2';
CREATE TABLESPACE
postgres=# \db+
List of tablespaces
Name | Owner | Location | Access privileges | Options | Size | Description
------------+-------+-------------+-------------------+---------+---------+-------------
pg_default | alice | | | | 22 MB |
pg_global | alice | | | | 573 kB |
space2 | alice | /tmp/space2 | | | 0 bytes |
(3 rows)We now have a new tablespace, of 0 size. Internally, within $PGDATA, Postgres stores this as a symlink:
/tmp$ ls -l data/pg_tblspc
total 0
lrwxrwxrwx 1 alice alice 11 May 8 11:47 16385 -> /tmp/space2The number 16385 is the OID of the tablespace.
Creating Objects
Most “CREATE” SQL commands come with a “TABLESPACE” option using which you can specify the tablespace in which to create that SQL object. Let’s try a few:
postgres=# create database foo tablespace space2;
CREATE DATABASE
postgres=# \c foo
You are now connected to database "foo" as user "alice".
foo=# create table footab1 (a int);
CREATE TABLE
foo=# create table footab2 (a int) tablespace space2;
CREATE TABLE
foo=# create table footab3 (a int) tablespace pg_default;
CREATE TABLE
foo=#Here’s what happened:
- We created a database called “foo” in the tablespace “space2”. The default tablespace for all objects in the database also becomes space2.
- The tables “footab1” and “footab2” are created in space2. You can explicitly specify the tablespace for the table, or use the database’s default.
- The table “footab3” is created in the pg_default tablespace. It is possible to have only some objects in another tablespace.
Moving Objects
You can also move existing objects, from existing databases into a different tablespace. Here’s how we can move one of our tables into another tablespace:
foo=# alter table footab2 set tablespace pg_default;
ALTER TABLEYou can also move all tables (or indexes) in one tablespace into another:
foo=# alter table all in tablespace space2 set tablespace pg_default;
ALTER TABLEAffected tables are locked while being relocated.
Tablespace Properties
A common use for tablespaces is to move indexes or tables onto a faster filesystem, for example, a new fast NVMe SSD or a EBS volume with higher IOPS. Informing the PostgreSQL query planner about how fast your new tablespace is lets it do a better job at estimating query execution times.
Typically, you’ll benchmark the sequential and random disk access performance for your tablespaces, and assign them relative numbers. For example, if your new tablespace is twice as fast for sequential and random disk access as compared to your “regular” tablespace, you can:
foo=# alter tablespace space2 set ( seq_page_cost=0.5, random_page_cost=0.5 );
ALTER TABLESPACEwhile leaving these values at “1.0” (the default) for the “regular” tablespace. For more information, see the documentation of seq_page_cost and random_page_cost.
There is also one more option, effective_io_concurrency, which can speed up bitmap heap scans if set.
Temporary Objects
Temporary tables and indexes are created by PostgreSQL either when explicitly asked to (“CREATE TEMP TABLE..”) or when it needs to hold large datasets temporarily for completing a query.
It is possible to tell PostgreSQL to place such objects in a separate tablespace. For example, if too many temporary tables are created in normal course, it might be possible to speed up your queries by placing such objects in a tablespace with faster hardware, faster/unjournaled/uncompressed filesystems, or even in-memory filesystems.
Use the option temp_tablespaces to tell Postgres which tablespace to use for creating temporary tables.
Connection-Default Tablespace
You can make clients create objects in a specific tablespace by default. This can be set as an option in a connection string or a client startup script, so that all newly created objects go into a new tablespace.
default_tablespace is the option you want to use for this.
Backup
Using pg_basebackup to back up a PostgreSQL cluster that has multiple
tablespaces needs a couple of extra steps.
If you’re using tarball-format backup, each tablespace comes out as it’s own tarball (with the tablespace OID as the filename). While restoring, this must be restored to the same path (like “/tmp/space2”) that used to be present while restoring. This is probably a bit of a pain because the backup script needs to store this additional information also somewhere alongside the backup.
Here’s how the tarball backup happens:
/tmp$ pg_basebackup --format=t --gzip --compress=9 -D tarbackup
/tmp$ ls -l tarbackup
total 3684
-rw-r--r-- 1 alice alice 937355 May 8 13:22 16385.tar.gz
-rw-r--r-- 1 alice alice 2812516 May 8 13:22 base.tar.gz
-rw------- 1 alice alice 19259 May 8 13:22 pg_wal.tar.gzFor plain format backups, it is possible to specify a new location for each tablespace. The data from each tablespace is written out into a new location. Every tablespace (other than pg_default and pg_global) must be mapped to a new location in the command-line, like this:
/tmp$ pg_basebackup --format=p --tablespace-mapping=/tmp/space2=/tmp/space2backup -D plainbackup
/tmp$ ls -l plainbackup/pg_tblspc/
total 0
lrwxrwxrwx 1 alice alice 17 May 8 13:35 16385 -> /tmp/space2backupStreaming Replication
Setting up a new standby for a primary that already has tablespaces involves bringing over the main data directory and each tablespace directories over to the standby. If you’re using pg_basebackup to do this, then use the plain format backup to also specify appropriate new locations for the tablespaces on the standby.
Creating a tablespace on the primary of a replicated server is bit tricker, because the paths for the new tablespace go over unmodified to the standby. The standby server expects an existing directory at the same location as in the primary, and creates a tablespace at that location. Typically, you’d want to:
- prepare and mount filesystems at both primary and standby, mount points have to be the same
- create empty directories within mount points if needed
- create tablespace at primary
Relocating Tablespaces
It is not possible to alter the location of a tablespace directly – you can’t for example, change “/tmp/space2” to “/mnt/space2” through any command. However, it is possible to:
- stop the PostgreSQL server process
- update the symlink in
$PGDATA/pg_tblspc - start the PostgreSQL server process
Uses
What all can you use tablespaces for? Here are some issues that can be overcome with tablespaces:
- Database growth: If for whatever reasons you can’t grow the filesystem that your database lives in, you can create new tablespaces in other mounted filesystems, and move existing objects and/or use the new tablespace as future default for objects.
- Compression: Have a table with very compressible data? Try moving it to a tablespace on a ZFS filesystem that has compression enabled.
- Fast indexes: You can move indexes or tables onto another filesystem that is faster/has more provisioned IOPS to speed up important queries. Be sure to adjust the tablespace options to tell the query planner how fast the new tablespace is!
Monitoring Using pgDash
pgDash is an in-depth monitoring solution designed specifically for PostgreSQL deployments. pgDash shows you information and metrics about every aspect of your PostgreSQL database server, collected using the open-source tool pgmetrics.
Among other things, pgDash can display your tablespace metrics and their changes over time:
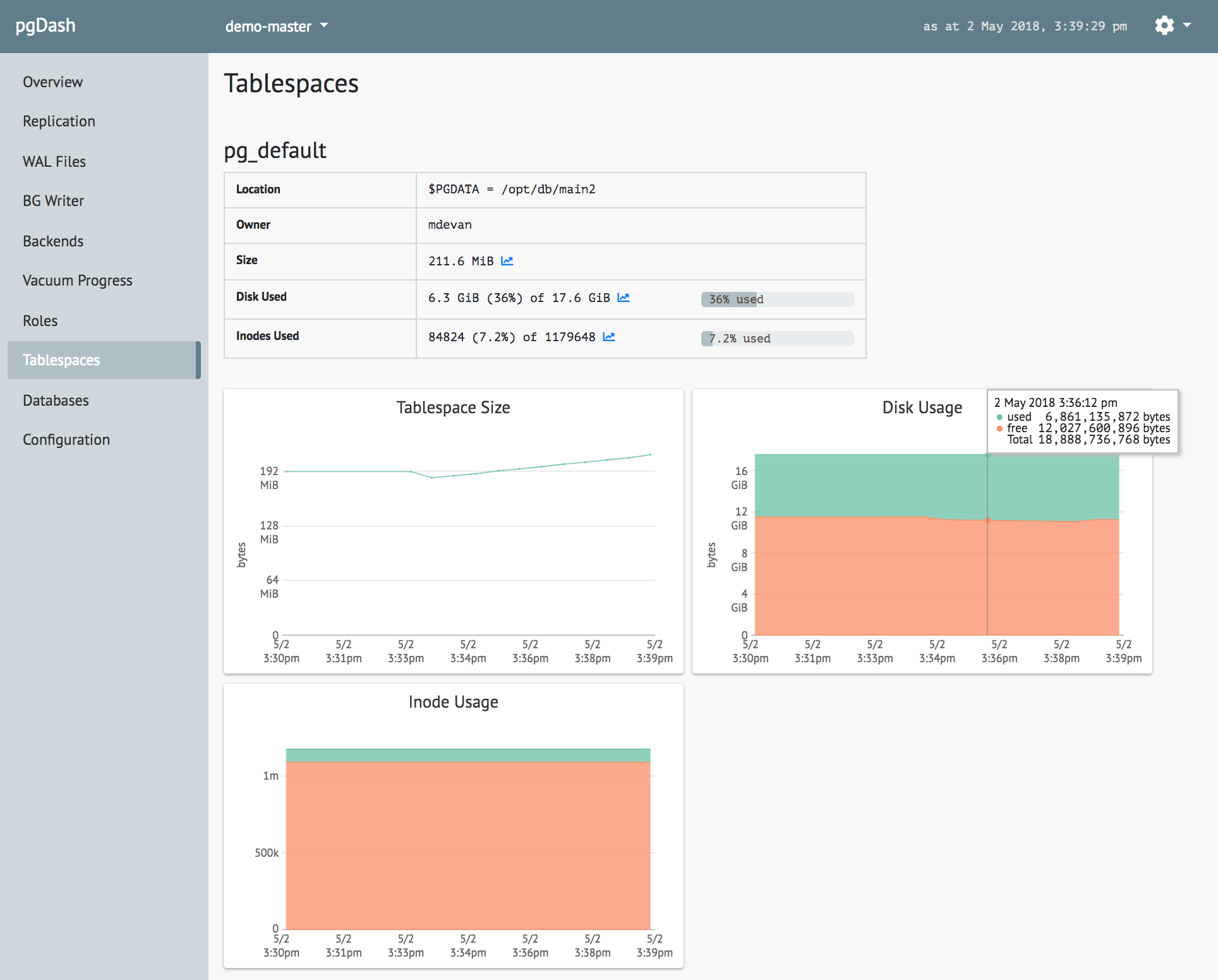
pgDash provides core reporting and visualization functionality, including collecting and displaying PostgreSQL information and providing time-series graphs and detailed reports. We’re actively working to enhance and expand pgDash to include alerting, baselines, teams, and more.